Data Engineering Zoomcamp — бесплатный курс по Data Engineering и построению data-pipeline
Содержание показать
Обзор Data Engineering Zoomcamp от DataTalksClub. Что это за курс, чему он учит, структура модулей и где изучать материалы.
Data Engineering Zoomcamp — это бесплатный образовательный курс и набор учебных материалов, который учит основам Data Engineering. Проект создан сообществом DataTalksClub и размещён на GitHub, где доступны все лекции, задания и примеры кода.
Главная цель курса — научить создавать полноценные data-pipeline, используя реальные инструменты индустрии.
Что такое Data Engineering Zoomcamp
Data Engineering Zoomcamp — это интенсивный курс длительностью около 9–10 недель, который постепенно обучает основам работы с данными и инфраструктурой обработки данных.
Во время обучения участники строят end-to-end pipeline — систему, которая:
-
собирает данные
-
обрабатывает их
-
хранит в хранилище
-
подготавливает для аналитики
Курс полностью бесплатный и доступен для самостоятельного изучения.
Официальный репозиторий:
https://github.com/DataTalksClub/data-engineering-zoomcamp
Для чего нужен этот курс
Zoomcamp предназначен для тех, кто хочет освоить профессию Data Engineer.
Он помогает:
-
изучить архитектуру обработки данных
-
научиться строить data-pipeline
-
работать с облачными сервисами
-
освоить инструменты Big Data
-
создать портфолио проектов
Курс часто используют начинающие специалисты, которые хотят перейти в сферу работы с данными.
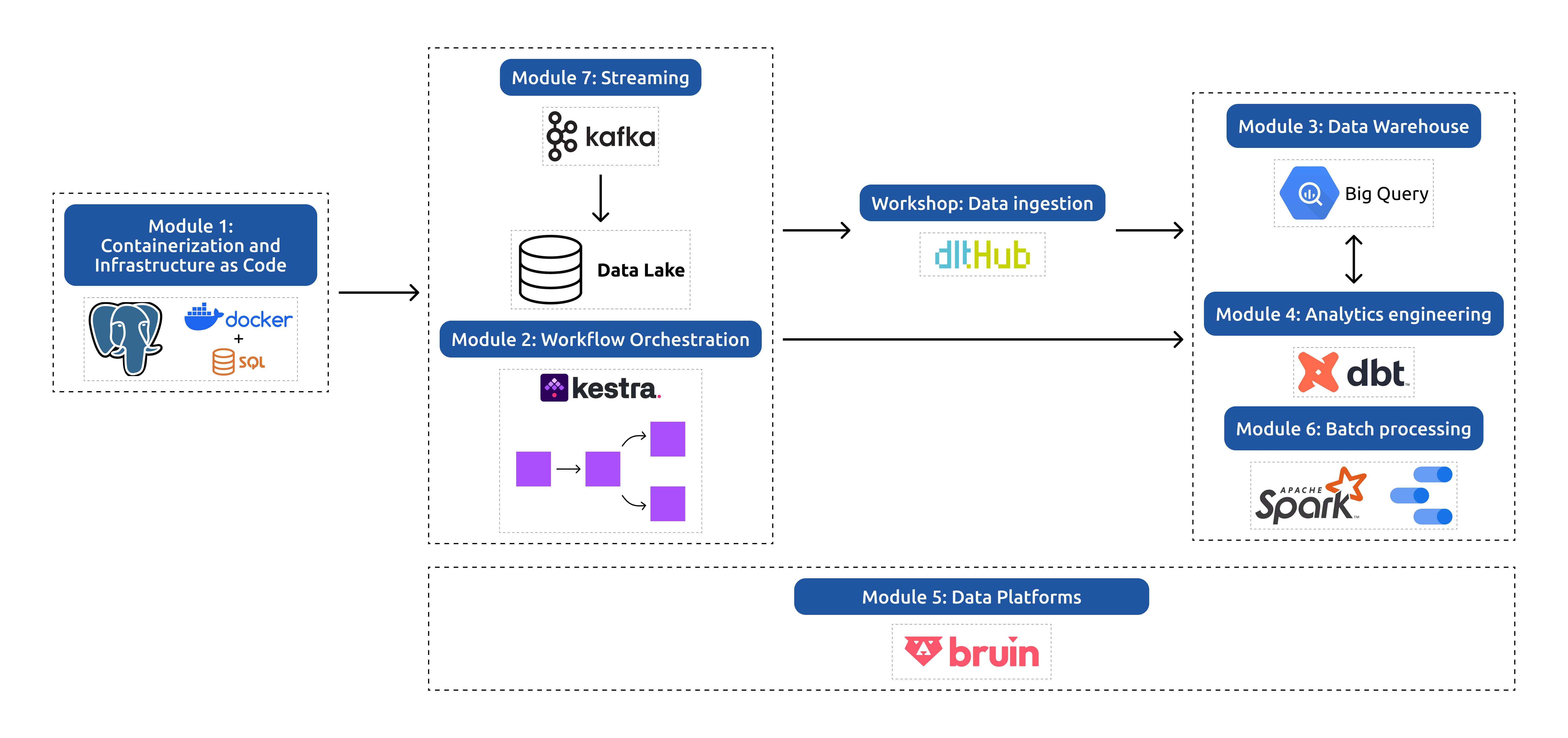
Что изучают на курсе
Программа разделена на несколько модулей, каждый из которых посвящён отдельной части data-инфраструктуры.
| Модуль | Темы |
|---|---|
| Containerization & Infrastructure | Docker, PostgreSQL, Terraform, настройка облачной инфраструктуры |
| Workflow Orchestration | Data Lakes и оркестрация процессов |
| Data Warehousing | работа с BigQuery, партиционирование и оптимизация |
| Analytics Engineering | моделирование данных и работа с dbt |
| Data Platforms | построение data-pipeline и обработка данных |
| Batch Processing | Apache Spark и обработка больших данных |
| Streaming | Kafka, потоковая обработка данных |
| Final Project | создание полноценного проекта data-pipeline |
Все материалы сопровождаются заданиями и практическими упражнениями.
Какие технологии используются
Во время курса изучаются инструменты, которые широко используются в индустрии data engineering.
Основные технологии:
-
Docker
-
Terraform
-
PostgreSQL
-
Google Cloud Platform
-
BigQuery
-
dbt
-
Apache Spark
-
Kafka
Освоение этих инструментов помогает понять, как строятся реальные системы обработки данных.
Как устроен репозиторий курса
GitHub-репозиторий используется как основной источник материалов.
Структура проекта выглядит примерно так:
| Папка | Содержимое |
|---|---|
| 01-docker-terraform | инфраструктура и контейнеризация |
| 02-workflow-orchestration | управление data-pipeline |
| 03-data-warehouse | работа с хранилищами данных |
| 04-analytics-engineering | моделирование данных |
| 05-data-platforms | создание платформ обработки |
| 06-batch | пакетная обработка данных |
| 07-streaming | потоковая обработка |
| projects | финальные проекты |
В каждой папке находятся:
-
инструкции
-
код
-
задания
-
ссылки на лекции.
Требования к участникам
Для прохождения курса желательно иметь базовые знания программирования.
Рекомендуемые навыки:
-
базовый Python
-
SQL
-
основы работы с Linux
-
понимание баз данных
Однако предыдущий опыт работы с Data Engineering не обязателен.
Как начать обучение
Чтобы начать изучение курса:
-
Перейдите в репозиторий проекта
https://github.com/DataTalksClub/data-engineering-zoomcamp -
Изучите README и структуру модулей.
-
Смотрите лекции и выполняйте задания.
-
Пройдите финальный проект.
Все материалы доступны бесплатно и могут изучаться в любом темпе.



Информация